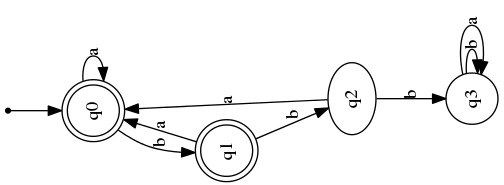
So, I was trying to reimplement [Zaki et al 2009, "VOGUE: A Variable Order Hidden Markov Modelwith Duration based on Frequent Sequence Mining"] where they describe VGS, an algorithm for frequent k-subsequence mining while keeping track of the gap symbols. The author has the VGS algorithm implemented in python already, but I decided to implement my own "simulation" of VGS in a map-reduce way.
Here's the code of the function, it accepts a sequence as a python list of objects (tested only with strings though), a minimum support minsup and a maximum gap maxgap between symbols, and it returns a record of the kind {k-subsequence :, (Frequency : , Gap_Symbols :
An example (from the VOGUE paper):
I hope someone finds that useful. Sorry if I re-invented the wheel. I am sure there are faster ways to do it but I needed to build on that.
Explanation:
As described in [Zaki, 2001], map every symbol s in our sequence S, to its position in S. For example the first 2 items will be: [(A, 1), (C, 2), ...].
Then we reduce to F1 = {A: [1, 5, ...], B: [3, ...] } and filter out those elements that appear less tha
n minsup.
Then combine F1 with itself. I.e produce [(AB, [1,3]), (AB, [5,8]), ...] keeping only those elements that have a maximum gap of maxgap. Subsequently, reduce that again to F_k = {AB: [[1,3],[5,8],...],...} and filter out based on the minsup value.
Repeat the same by combining F_k with F_1 until you have reached the desired subsequence length k.
Here's the code of the function, it accepts a sequence as a python list of objects (tested only with strings though), a minimum support minsup and a maximum gap maxgap between symbols, and it returns a record of the kind {k-subsequence :
- }:
An example (from the VOGUE paper):
>>> seq = list("ACBDAHCBADFGAIEB")>>> print find_frequent_subsequences(seq,3, 2, 3){('A', 'C', 'A'): (2, ['H']), ('C', 'B', 'A'): (2, []), ('C', 'B', 'D'): (2, []), ('A', 'B', 'A'): (2, ['C', 'H', 'C']), ('A', 'C', 'B'): (2, ['H']), ('A', 'B', 'D'): (2, ['C', 'H', 'C']), ('C', 'D', 'A'): (2, ['B', 'B', 'A']), ('D', 'A', 'B'): (2, ['F', 'G']), ('A', 'C', 'D'): (2, ['H']), ('A', 'D', 'A'): (2, ['C', 'B']), ('B', 'D', 'A'): (2, ['A'])}
I hope someone finds that useful. Sorry if I re-invented the wheel. I am sure there are faster ways to do it but I needed to build on that.
Explanation:
As described in [Zaki, 2001], map every symbol s in our sequence S, to its position in S. For example the first 2 items will be: [(A, 1), (C, 2), ...].
Then we reduce to F1 = {A: [1, 5, ...], B: [3, ...] } and filter out those elements that appear less tha
n minsup.
Then combine F1 with itself. I.e produce [(AB, [1,3]), (AB, [5,8]), ...] keeping only those elements that have a maximum gap of maxgap. Subsequently, reduce that again to F_k = {AB: [[1,3],[5,8],...],...} and filter out based on the minsup value.
Repeat the same by combining F_k with F_1 until you have reached the desired subsequence length k.